
运行环境
计算机类型:笔记本
CPU:i9-13900H
内存:64GB
硬盘:3T
GPU:RTX 4060 8GB
操作系统:Win11
大模型环境:Ollama
速度测试
模型
量化
模型大小
运行大小
速度
qwen3:0.6b
fp16
1.5 GB
2.0 GB
129.09 tokens/s
qwen3:4b
fp16
8.1 GB
9.2 GB
14.72 tokens/s
qwen3:8b
q4
5.2 GB
6.0 GB
43.50 tokens/s
qwen3:14b
q4
9.3 GB
10 GB
10.81 tokens/s
qwen3:30b-a3b
q4
18 GB
20 GB
9.52 tokens/s
凡是运行大小是8GB以上的,都会使用部分内存,使用CPU/GPU混合推理。
个人评价
这次Qwen3发布的模型,给了我以下几个惊喜。
最小模型0.6B。速度超快(259.03 tokens/s),最小的qwen3:0.6b q4量化版本才522 MB。而且这个模型并非什么问题都是。对于某些问题,比如科普常识,解答比较靠谱。
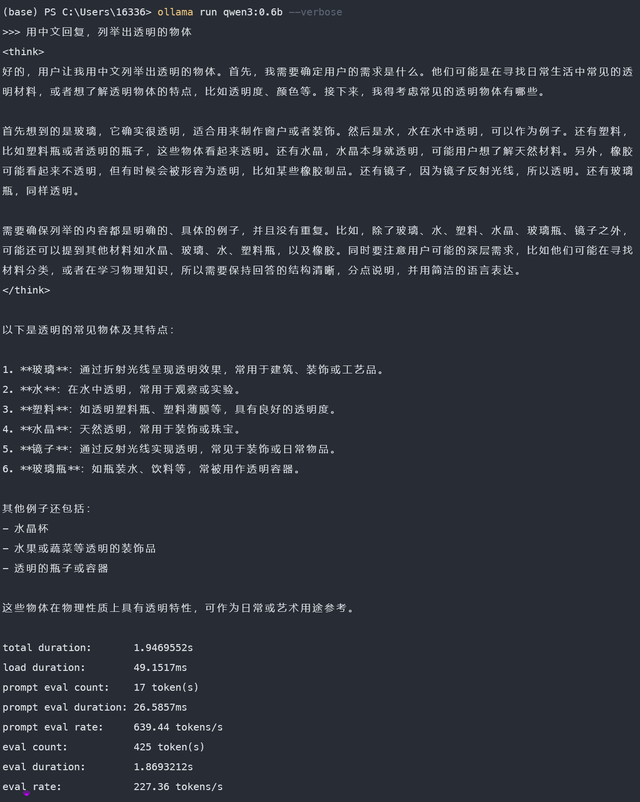
qwen3:30b-a3b 模型是一个MoE模型。我笔记本这配置,强行30B的Dense模型,速度会非常非常慢。但是MoE模型,每次激活3B,速度还可以。回答的也棒。
这一系列模型,上下文长度非常长。回答的内容可以有两三千tokens。

